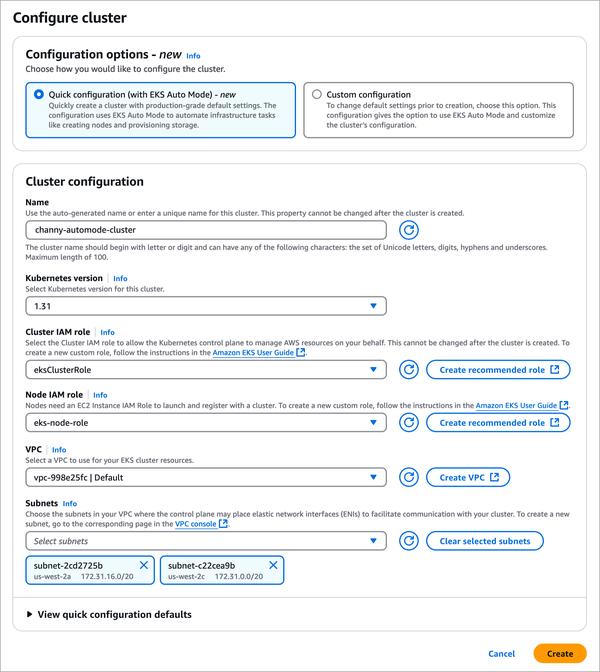
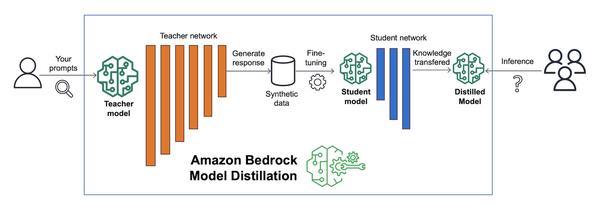
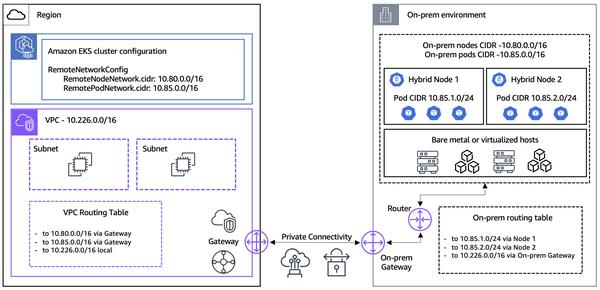
Confluent ने Google Cloud के सहयोग से एक ब्लॉग पोस्ट जारी किया है जिसमें बताया गया है कि कैसे संगठन SQL क्वेरी जनरेशन को स्वचालित करने के लिए बड़े भाषा मॉडल (LLM) का लाभ उठा सकते हैं, जिससे डेटा एनालिटिक्स वर्कफ़्लो को सुव्यवस्थित किया जा सकता है। लेख में Confluent और Vertex AI के साथ LLM को एकीकृत करके रीयल-टाइम डेटा प्रोसेसिंग और अंतर्दृष्टि के लिए एक शक्तिशाली, एंड-टू-एंड समाधान प्रस्तुत किया गया है।
जिस चीज़ ने विशेष रूप से मेरा ध्यान खींचा, वह थी सीमित SQL विशेषज्ञता वाले व्यावसायिक उपयोगकर्ताओं को डेटासेट का कुशलतापूर्वक पता लगाने के लिए सशक्त बनाने की LLM की क्षमता। प्राकृतिक भाषा संकेतों का लाभ उठाकर, उपयोगकर्ता जटिल SQL क्वेरी तैयार किए बिना सिस्टम के साथ इंटरैक्ट कर सकते हैं और मूल्यवान अंतर्दृष्टि प्राप्त कर सकते हैं।
इस तकनीक द्वारा संबोधित की जाने वाली प्रमुख समस्याओं में से एक जटिल SQL क्वेरी लिखने से जुड़ी चुनौतियाँ हैं। ऐसी क्वेरी लिखने और उनका अनुकूलन करने के लिए अक्सर विशेष डेटा इंजीनियरिंग कौशल की आवश्यकता होती है और इसमें समय भी लगता है। LLM का उपयोग करके इस प्रक्रिया को स्वचालित करके, संगठन त्रुटियों के जोखिम को कम करते हुए समय और संसाधनों की बचत कर सकते हैं।
इसके अलावा, Confluent की रीयल-टाइम स्ट्रीमिंग क्षमताओं के साथ LLM को एकीकृत करने से रीयल-टाइम डेटा विश्लेषण के मुद्दे का समाधान होता है। पारंपरिक बैच प्रोसेसिंग विधियों के विपरीत, जिनमें अक्सर रीयल-टाइम निर्णय लेने के लिए आवश्यक गति और चपलता का अभाव होता है, यह समाधान यह सुनिश्चित करता है कि अंतर्दृष्टि आसानी से उपलब्ध हो, जिससे व्यवसाय सक्रिय निर्णय ले सकें।
कुल मिलाकर, मुझे लगता है कि डेटा एनालिटिक्स के क्षेत्र में LLM, Confluent और Vertex AI का एकीकरण एक महत्वपूर्ण कदम है। SQL क्वेरी जनरेशन को स्वचालित करके और रीयल-टाइम स्ट्रीमिंग को सक्षम करके, यह समाधान संगठनों को पारंपरिक चुनौतियों से उबरने और अपने डेटा के पूर्ण मूल्य को अनलॉक करने का अधिकार देता है।