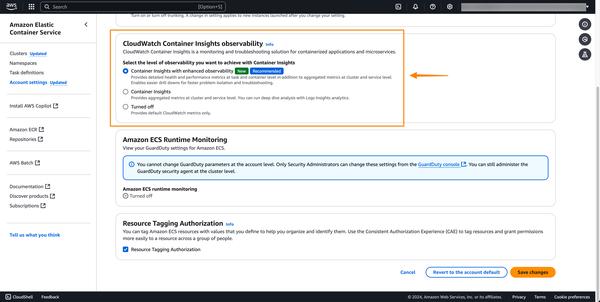
Amazon Data Firehose ने PostgreSQL, MySQL जैसे डेटाबेस से बदलावों को कैप्चर करने और Amazon S3 पर Apache Iceberg टेबल में अपडेट को दोहराने की एक नई क्षमता पेश की है। यह ट्रांजेक्शन परफॉर्मेंस को प्रभावित किए बिना डेटाबेस अपडेट को स्ट्रीम करने के लिए एक सरल, एंड-टू-एंड समाधान प्रदान करता है। उपयोगकर्ता अपने डेटाबेस से परिवर्तन डेटा कैप्चर (CDC) अपडेट देने के लिए मिनटों में एक Data Firehose स्ट्रीम सेट कर सकते हैं। अब वे विभिन्न डेटाबेस से डेटा को Amazon S3 पर Iceberg टेबल में आसानी से दोहरा सकते हैं और बड़े पैमाने पर एनालिटिक्स और मशीन लर्निंग (ML) अनुप्रयोगों के लिए अप-टू-डेट डेटा का उपयोग कर सकते हैं। AWS एंटरप्राइज ग्राहक आमतौर पर ट्रांजेक्शनल अनुप्रयोगों के लिए सैकड़ों डेटाबेस का उपयोग करते हैं। नवीनतम डेटा पर बड़े पैमाने पर एनालिटिक्स और ML करने के लिए, वे डेटाबेस में किए गए बदलावों को कैप्चर करना चाहते हैं, जैसे कि जब किसी टेबल में रिकॉर्ड डाले जाते हैं, संशोधित किए जाते हैं या हटाए जाते हैं, और अपने डेटा वेयरहाउस या Amazon S3 डेटा लेक में Apache Iceberg जैसे ओपन-सोर्स टेबल फॉर्मेट में अपडेट देते हैं। कई ग्राहक डेटाबेस से समय-समय पर पढ़ने के लिए एक्सट्रेक्ट, ट्रांसफॉर्म और लोड (ETL) जॉब विकसित करते हैं। हालाँकि, ETL रीडर डेटाबेस ट्रांजेक्शन परफॉर्मेंस को प्रभावित करते हैं, और बैच जॉब डेटा के एनालिटिक्स के लिए उपलब्ध होने से पहले कई घंटों की देरी जोड़ सकते हैं। इसे कम करने के लिए, ग्राहक डेटाबेस में किए गए बदलावों को स्ट्रीम करना चाहते हैं, जिसे CDC स्ट्रीम कहा जाता है। इस नई डेटा स्ट्रीमिंग क्षमता के साथ, Data Firehose डेटाबेस से Amazon S3 पर Apache Iceberg टेबल में CDC स्ट्रीम को प्राप्त करने और लगातार दोहराने की क्षमता जोड़ता है। उपयोगकर्ता स्रोत और गंतव्य निर्दिष्ट करके एक Data Firehose स्ट्रीम सेट करते हैं। Data Firehose एक प्रारंभिक डेटा स्नैपशॉट और चयनित डेटाबेस टेबल में बाद के सभी परिवर्तनों को डेटा स्ट्रीम के रूप में कैप्चर करता है और दोहराता है। CDC स्ट्रीम प्राप्त करने के लिए, Data Firehose डेटाबेस प्रतिकृति लॉग का उपयोग करता है, जिससे डेटाबेस ट्रांजेक्शन परफॉर्मेंस पर प्रभाव कम होता है। जब डेटाबेस अपडेट की मात्रा में उतार-चढ़ाव होता है, तो Data Firehose स्वचालित रूप से डेटा को विभाजित करता है और रिकॉर्ड को तब तक बनाए रखता है जब तक कि वे वितरित नहीं हो जाते। उपयोगकर्ताओं को क्षमता का प्रावधान करने या क्लस्टर का प्रबंधन करने की आवश्यकता नहीं है। Data Firehose प्रारंभिक स्ट्रीम निर्माण के दौरान डेटाबेस टेबल के समान स्कीमा का उपयोग करके स्वचालित रूप से Apache Iceberg टेबल भी बना सकता है और स्रोत स्कीमा परिवर्तनों के आधार पर लक्ष्य स्कीमा को स्वचालित रूप से विकसित कर सकता है। पूरी तरह से प्रबंधित सेवा के रूप में, Data Firehose ओपन-सोर्स घटकों, सॉफ़्टवेयर अपडेट या परिचालन ओवरहेड की आवश्यकता को समाप्त करता है।
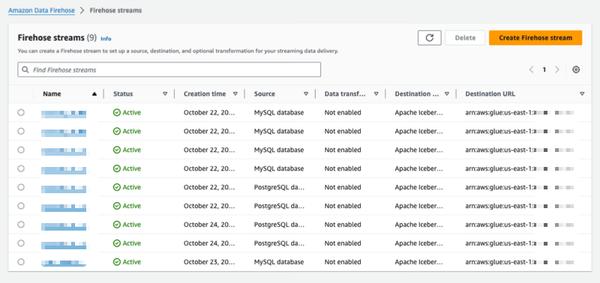
Amazon Data Firehose का उपयोग करके डेटाबेस से Apache Iceberg टेबल में बदलावों को दोहराएँ (पूर्वावलोकन में)
AWS