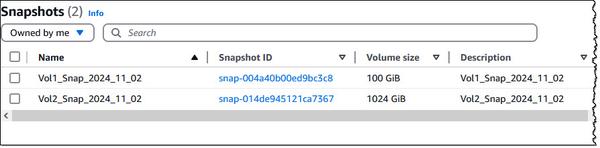
Amazon Bedrock ने नए RAG मूल्यांकन और LLM-as-a-judge क्षमताओं की घोषणा की है, जो जनरेटिव AI अनुप्रयोगों के परीक्षण और सुधार को सरल बनाता है। Amazon Bedrock नॉलेज बेस अब RAG मूल्यांकन का समर्थन करता है, जिससे आप रिट्रीवल ऑग्मेंटेड जेनरेशन (RAG) अनुप्रयोगों का आकलन और अनुकूलन करने के लिए एक स्वचालित नॉलेज बेस मूल्यांकन चला सकते हैं। यह मूल्यांकन मेट्रिक्स की गणना के लिए एक बड़े भाषा मॉडल (LLM) का उपयोग करता है, जिससे विभिन्न कॉन्फ़िगरेशन की तुलना और इष्टतम परिणामों के लिए ट्यूनिंग संभव हो पाती है। Amazon Bedrock मॉडल मूल्यांकन में अब LLM-as-a-judge शामिल है, जो लागत और समय के एक अंश पर मानव-जैसी गुणवत्ता वाले अन्य मॉडलों के परीक्षण और मूल्यांकन की अनुमति देता है। ये क्षमताएं AI अनुप्रयोगों का तेज़, स्वचालित मूल्यांकन प्रदान करती हैं, फ़ीडबैक लूप को छोटा करती हैं और सुधारों को गति देती हैं। मूल्यांकन में शुद्धता, सहायकता, और उत्तर देने से इनकार और हानिकारकता जैसे ज़िम्मेदार AI मानदंड जैसे गुणवत्ता आयामों का आकलन किया जाता है। परिणाम प्रत्येक स्कोर के लिए प्राकृतिक भाषा स्पष्टीकरण प्रदान करते हैं, जिन्हें आसान व्याख्या के लिए 0 से 1 तक सामान्यीकृत किया जाता है। पारदर्शिता के लिए दस्तावेज़ीकरण में रूब्रिक और जज प्रॉम्प्ट प्रकाशित किए जाते हैं।
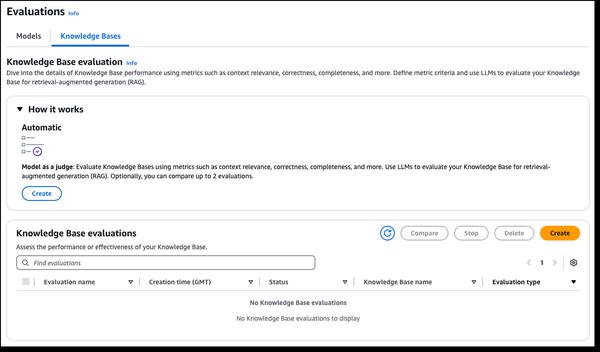
Amazon Bedrock में नए RAG मूल्यांकन और LLM-as-a-judge क्षमताएं
AWS